From research notebooks to production APIs
Memory-efficient storage and querying for annotated text corpora. Compatible with 35+ Text-Fabric datasets. Scales from laptops to AI-powered pipelines.
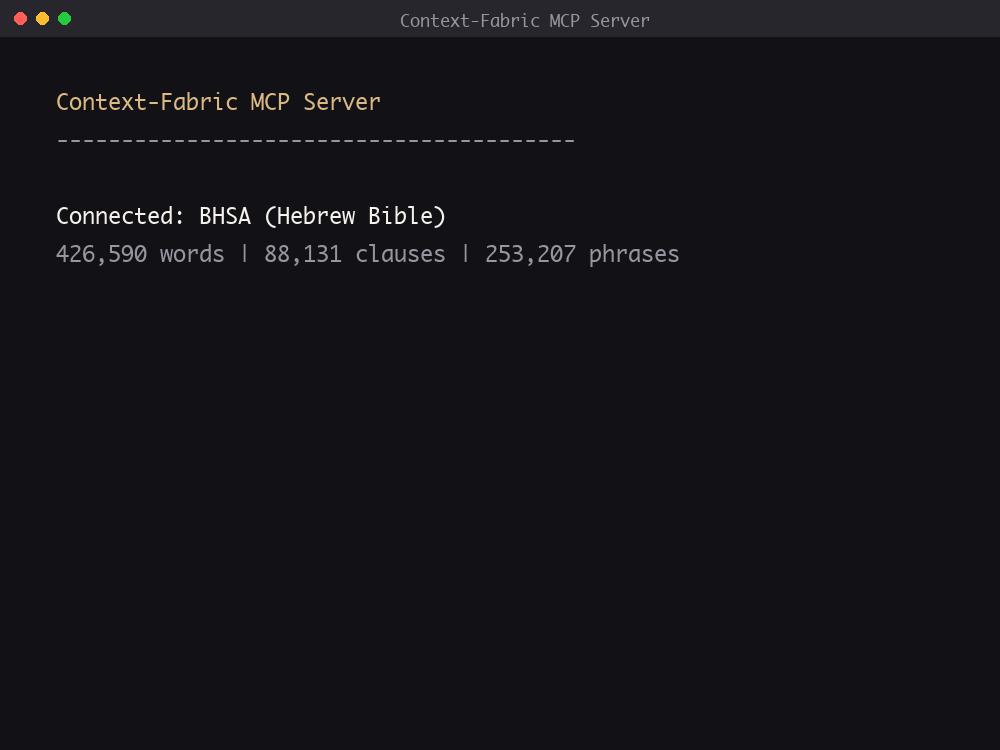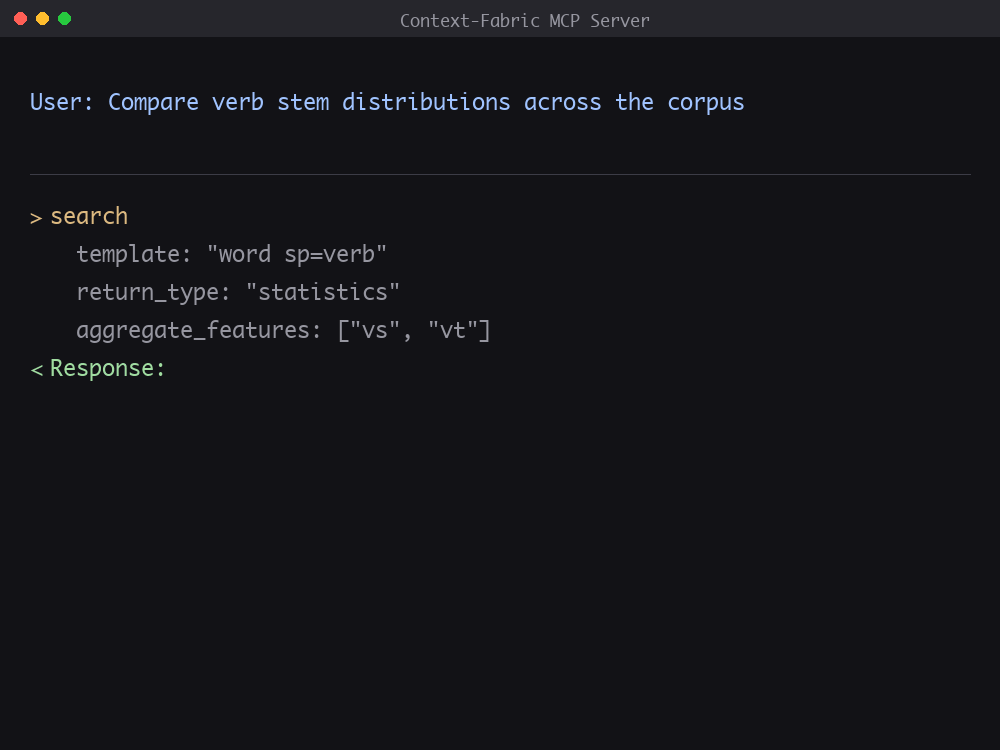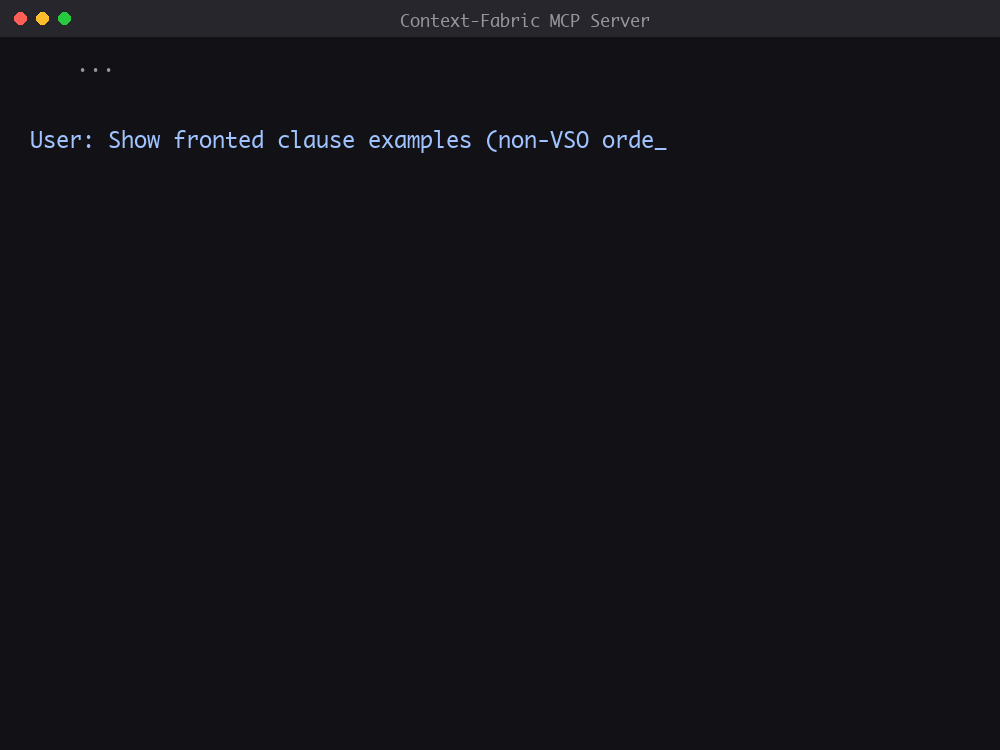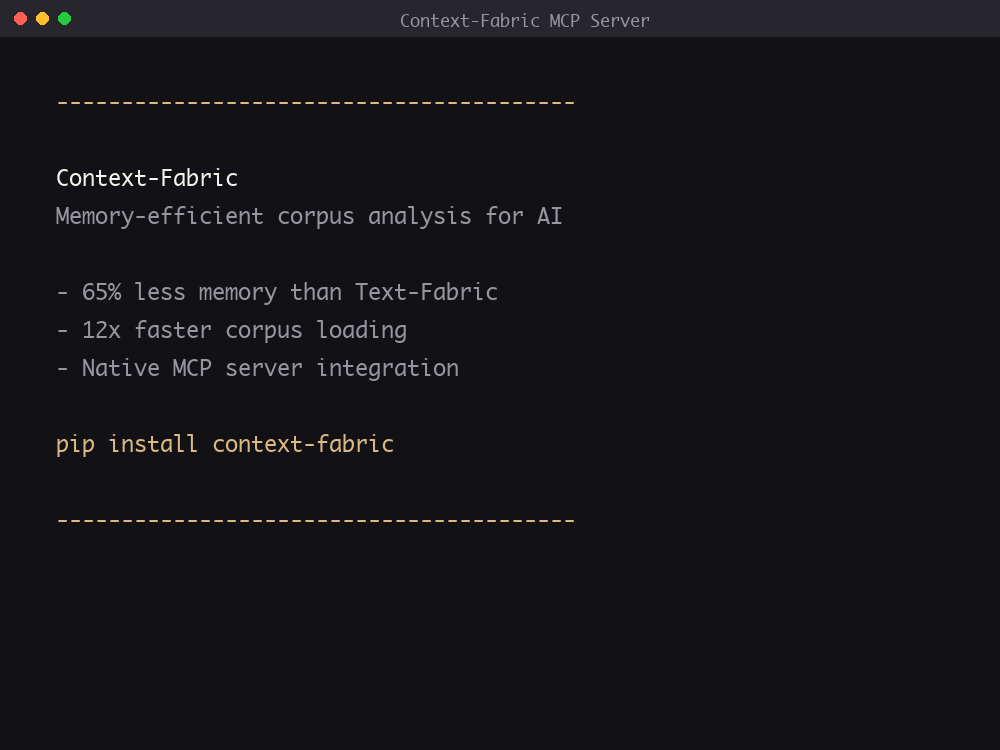
AI agent querying BHSA corpus via MCP protocol
Built for corpus linguistics at any scale
Whether you're exploring in a notebook or deploying at scale, the same architecture delivers.
Memory-Mapped Storage
Data lives on disk, not in memory, so you can load more corpora at once. In production, multiple workers share the same pages. 92% less memory whether you're running locally or at scale.
AI Agent Integration
Built-in MCP server enables Claude, ChatGPT, Cursor, and any MCP-compatible agent to query corpora through natural language. Bringing computational linguistics to conversational interfaces.
Graph-Based Model
Nodes represent textual units—morphemes, words, phrases, clauses. Edges capture syntax, coreference, discourse. Navigate with elegant traversal APIs.
Pattern Search
SPIN algorithm finds complex linguistic patterns across massive corpora. Query by lemma, part-of-speech, syntactic role—instant results.
92%*
Less Memory
12x*
Faster Loading
35+
Corpora
Zero
Data Copies
*Compared to Text-Fabric with BHSA
Clean, familiar API
If you know Text-Fabric, you know Context-Fabric. The same familiar API with dramatically better performance.
from cfabric import Fabric
# Load corpus with memory-mapped storage
CF = Fabric('path/to/bhsa')
api = CF.loadAll()
# Search for patterns
query = '''
verse
word lex=MLK
'''
for result in api.S.search(query):
print(api.T.text(result))# Traverse linguistic hierarchy
for word in api.N.walk('word'):
# Access features
pos = api.F.sp.v(word)
lex = api.F.lex.v(word)
# Move up the hierarchy
clause = api.L.u(word, 'clause')
# Render text
text = api.T.text(word)Ready to explore?
Install Context-Fabric and start querying linguistic corpora in minutes.